
Discrete distribution function. Distribution function of a random variable
Find:
a) parameter A ;
b) distribution function F(x) ;
c) the probability of hitting a random variable X in the interval ;
d) mathematical expectation MX and variance DX .
Plot the functions f(x) and F(x) .
Task 2. Find the variance of the random variable X given by the integral function.
Task 3. Find the mathematical expectation of a random variable X given a distribution function.
Task 4. The probability density of some random variable is given as follows: f(x) = A/x 4 (x = 1; +∞)
Find coefficient A , distribution function F(x) , mathematical expectation and variance, as well as the probability that a random variable takes a value in the interval . Plot f(x) and F(x) graphs.
A task. The distribution function of some continuous random variable is given as follows:
Determine the parameters a and b , find the expression for the probability density f(x) , the mathematical expectation and variance, as well as the probability that the random variable will take a value in the interval . Plot f(x) and F(x) graphs.
Let's find the distribution density function as a derivative of the distribution function.
F′=f(x)=a
Knowing that we will find the parameter a: ![]()
or 3a=1, whence a = 1/3
We find the parameter b from the following properties:
F(4) = a*4 + b = 1
1/3*4 + b = 1 whence b = -1/3
Therefore, the distribution function is: F(x) = (x-1)/3


Dispersion.

 1 / 9 4 3 - (1 / 9 1 3) - (5 / 2) 2 = 3 / 4
1 / 9 4 3 - (1 / 9 1 3) - (5 / 2) 2 = 3 / 4
Find the probability that a random variable takes a value in the interval
P(2< x< 3) = F(3) – F(2) = (1/3*3 - 1/3) - (1/3*2 - 1/3) = 1/3
Example #1. The probability distribution density f(x) of a continuous random variable X is given. Required:
- Determine coefficient A .
- find the distribution function F(x) .
- schematically plot F(x) and f(x) .
- find the mathematical expectation and variance of X .
- find the probability that X takes a value from the interval (2;3).
Solution:
The random variable X is given by the distribution density f(x):
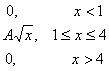
Find the parameter A from the condition:

or
14/3*A-1=0
Where,
A = 3 / 14

The distribution function can be found by the formula.

To find the distribution functions of random variables and their variables, it is necessary to study all the features of this field of knowledge. There are several different methods for finding the values in question, including changing a variable and generating a moment. Distribution is a concept based on such elements as dispersion, variations. However, they characterize only the degree of scattering range.
The more important functions of random variables are those that are related and independent, and equally distributed. For example, if X1 is the weight of a randomly selected individual from a population of males, X2 is the weight of another, ..., and Xn is the weight of another person from the male population, then we need to know how the random function X is distributed. In this case, the classical theorem called the central limit theorem applies. It allows us to show that for large n the function follows standard distributions.
Functions of one random variable
The central limit theorem is designed to approximate discrete values in question, such as binomial and Poisson. Distribution functions of random variables are considered, first of all, on simple values of one variable. For example, if X is a continuous random variable having its own probability distribution. In this case, we are exploring how to find the density function of Y using two different approaches, namely the distribution function method and the change in variable. First, only one-to-one values are considered. Then you need to modify the technique of changing the variable to find its probability. Finally, one needs to learn how the cumulative distribution can help model random numbers that follow certain sequential patterns.
Method of distribution of considered values
The method of the probability distribution function of a random variable is applicable in order to find its density. When using this method, a cumulative value is calculated. Then, by differentiating it, you can get the probability density. Now that we have the distribution function method, we can look at a few more examples. Let X be a continuous random variable with a certain probability density.
What is the probability density function of x2? If you look at or graph the function (top and right) y \u003d x2, you can note that it is an increasing X and 0 In the last example, great care was used to index the cumulative functions and the probability density with either X or Y to indicate which random variable they belonged to. For example, when finding the cumulative distribution function Y, we got X. If you need to find a random variable X and its density, then you just need to differentiate it. Let X be a continuous random variable given by a distribution function with a common denominator f(x). In this case, if you put the value of y in X = v (Y), then you get the value of x, for example v (y). Now, we need to get the distribution function of a continuous random variable Y. Where the first and second equality takes place from the definition of cumulative Y. The third equality holds because the part of the function for which u (X) ≤ y is also true that X ≤ v (Y ). And the latter is done to determine the probability in a continuous random variable X. Now we need to take the derivative of FY (y), the cumulative distribution function of Y, to get the probability density of Y. Let X be a continuous random variable with common f(x) defined over c1 To address this issue, quantitative data can be collected and an empirical cumulative distribution function can be used. With this information and appealing to it, you need to combine means samples, standard deviations, media data, and so on. Similarly, even a fairly simple probabilistic model can have a huge number of results. For example, if you flip a coin 332 times. Then the number of results obtained from flips is greater than that of google (10100) - a number, but not less than 100 quintillion times higher than elementary particles in the known universe. Not interested in an analysis that gives an answer to every possible outcome. A simpler concept would be needed, such as the number of heads, or the longest stroke of the tails. To focus on issues of interest, a specific result is accepted. The definition in this case is as follows: a random variable is a real function with a probability space. The range S of a random variable is sometimes called the state space. Thus, if X is the value in question, then so N = X2, exp ↵X, X2 + 1, tan2 X, bXc, and so on. The last of these, rounding X to the nearest whole number, is called the floor function. Once the distribution function of interest for the random variable x is determined, the question usually becomes: "What are the chances that X falls into some subset of the values of B?". For example, B = (odd numbers), B = (greater than 1), or B = (between 2 and 7) to indicate those results that have X, the value of the random variable, in subset A. So in the above example, you can describe the events as follows. (X is an odd number), (X is greater than 1) = (X > 1), (X is between 2 and 7) = (2 Thus, it is possible to calculate the probability that the distribution function of a random variable x will take values in the interval by subtracting. Consideration needs to be given to including or excluding endpoints. We will call a random variable discrete if it has a finite or countably infinite state space. Thus, X is the number of heads on three independent flips of a biased coin that goes up with probability p. We need to find the cumulative distribution function of a discrete random variable FX for X. Let X be the number of peaks in a collection of three cards. Then Y = X3 via FX. FX starts at 0, ends at 1, and does not decrease as x values increase. The cumulative FX distribution function of a discrete random variable X is constant, except for jumps. When jumping the FX is continuous. It is possible to prove the statement about the correct continuity of the distribution function from the probability property using the definition. It sounds like this: a constant random variable has a cumulative FX that is differentiable. To show how this can happen, we can give an example: a target with a unit radius. Presumably. the dart is evenly distributed over the specified area. For some λ> 0. Thus, the distribution functions of continuous random variables increase smoothly. FX has the properties of a distribution function. A man waits at a bus stop until the bus arrives. Having decided for himself that he will refuse when the wait reaches 20 minutes. Here it is necessary to find the cumulative distribution function for T. The time when a person will still be at the bus station or will not leave. Despite the fact that the cumulative distribution function is defined for each random variable. All the same, other characteristics will be used quite often: the mass for a discrete variable and the distribution density function of a random variable. Usually the value is output through one of these two values. These values are considered by the following properties, which are of a general (mass) nature. The first is based on the fact that the probabilities are not negative. The second follows from the observation that the set for all x=2S, the state space for X, forms a partition of the probabilistic freedom of X. Example: tossing a biased coin whose outcomes are independent. You can continue to perform certain actions until you get a throw of heads. Let X denote a random variable that gives the number of tails in front of the first head. And p denotes the probability in any given action. So, the mass probability function has the following characteristic features. Because the terms form a numerical sequence, X is called a geometric random variable. Geometric scheme c, cr, cr2,. , crn has a sum. And, therefore, sn has a limit as n 1. In this case, the infinite sum is the limit. The mass function above forms a geometric sequence with a ratio. Therefore, natural numbers a and b. The difference in values in the distribution function is equal to the value of the mass function. The density values under consideration have the following definition: X is a random variable whose distribution FX has a derivative. FX satisfying Z xFX (x) = fX (t) dt-1 is called the probability density function. And X is called a continuous random variable. In the fundamental theorem of calculus, the density function is the derivative of the distribution. You can calculate probabilities by calculating definite integrals. Because data are collected from multiple observations, more than one random variable at a time must be considered in order to model the experimental procedures. Therefore, the set of these values and their joint distribution for the two variables X1 and X2 means viewing events. For discrete random variables, joint probabilistic mass functions are defined. For continuous ones, fX1, X2 are considered, where the joint probability density is satisfied. Two random variables X1 and X2 are independent if any two events associated with them are the same. In words, the probability that two events (X1 2 B1) and (X2 2 B2) occur at the same time, y, is equal to the product of the variables above, that each of them occurs individually. For independent discrete random variables, there is a joint probabilistic mass function, which is the product of the limiting ion volume. For continuous random variables that are independent, the joint probability density function is the product of the marginal density values. Finally, n independent observations x1, x2, are considered. , xn arising from an unknown density or mass function f. For example, an unknown parameter in functions for an exponential random variable describing the waiting time for a bus. The main goal of this theoretical field is to provide the tools needed to develop inferential procedures based on sound principles of statistical science. Thus, one very important use case for software is the ability to generate pseudo-data to mimic actual information. This makes it possible to test and improve analysis methods before having to use them in real databases. This is required in order to explore the properties of the data through modeling. For many commonly used families of random variables, R provides commands for generating them. For other circumstances, methods for modeling a sequence of independent random variables that have a common distribution will be needed. Discrete Random Variables and Sample Command. The sample command is used to create simple and stratified random samples. As a result, if a sequence x is input, sample(x, 40) selects 40 records from x such that all choices of size 40 have the same probability. This uses the default R command for fetch without replacement. Can also be used to model discrete random variables. To do this, you need to provide a state space in the vector x and the mass function f. A call to replace = TRUE indicates that sampling occurs with replacement. Then, to give a sample of n independent random variables having a common mass function f, the sample (x, n, replace = TRUE, prob = f) is used. It is determined that 1 is the smallest value represented, and 4 is the largest of all. If the command prob = f is omitted, then the sample will sample uniformly from the values in vector x. You can check the simulation against the mass function that generated the data by looking at the double equals sign, ==. And recalculating the observations that take every possible value for x. You can make a table. Repeat this for 1000 and compare the simulation with the corresponding mass function. First, simulate homogeneous distribution functions of random variables u1, u2,. , un on the interval . About 10% of the numbers should be within . This corresponds to 10% simulations on the interval for a random variable with the FX distribution function shown. Similarly, about 10% of the random numbers should be in the interval . This corresponds to 10% simulations on the random variable interval with the distribution function FX. These values on the x axis can be obtained by taking the inverse from FX. If X is a continuous random variable with density fX positive everywhere in its domain, then the distribution function is strictly increasing. In this case, FX has an inverse FX-1 function known as the quantile function. FX (x) u only when x FX-1 (u). The probability transformation follows from the analysis of the random variable U = FX(X). FX has a range from 0 to 1. It cannot take values below 0 or above 1. For values of u between 0 and 1. If U can be modeled, then it is necessary to simulate a random variable with FX distribution via a quantile function. Take the derivative to see that the density u varies within 1. Since the random variable U has a constant density over the interval of its possible values, it is called uniform on the interval. It is modeled in R with the runif command. The identity is called a probabilistic transformation. You can see how it works in the dart board example. X between 0 and 1, the distribution function u = FX(x) = x2, and hence the quantile function x = FX-1(u). It is possible to model independent observations of the distance from the center of the dart panel, while generating uniform random variables U1, U2,. , Un. The distribution function and the empirical function are based on 100 simulations of the distribution of a dart board. For an exponential random variable, presumably u = FX (x) = 1 - exp (- x), and hence x = - 1 ln (1 - u). Sometimes logic consists of equivalent statements. In this case, you need to concatenate the two parts of the argument. The intersection identity is similar for all 2 (S i i) S, instead of some value. The union Ci is equal to the state space S and each pair is mutually exclusive. Since Bi - is divided into three axioms. Each check is based on the corresponding probability P. For any subset. Using an identity to make sure the answer doesn't depend on whether the interval endpoints are included. For each outcome in all events, the second property of the continuity of probabilities is ultimately used, which is considered axiomatic. The law of distribution of the function of a random variable here shows that each has its own solution and answer. The result of any random experiment can be characterized qualitatively and quantitatively. Qualitative the result of a random experiment - random
event. Any quantitative characteristic, which as a result of a random experiment can take one of a certain set of values, - random value. Random value
is one of the central concepts of probability theory. Let be an arbitrary probability space. Random variable is a real numerical function x \u003d x (w), w W , such that for any real x Event
usually written as x< x. In the following, random variables will be denoted by lowercase Greek letters x, h, z, …
A random variable is the number of points that fell when throwing a dice, or the height of a student randomly selected from the study group. In the first case, we are dealing with discrete random variable(it takes values from a discrete number set M=(1, 2, 3, 4, 5, 6) ; in the second case, with continuous random variable(it takes values from a continuous number set - from the interval of the number line I=). Each random variable is completely determined by its distribution function. If x . is a random variable, then the function F(x) = Fx(x)
= P(x< x) is called distribution function random variable x . Here P(x<x) - the probability that the random variable x takes a value less than x. It is important to understand that the distribution function is a "passport" of a random variable: it contains all the information about the random variable and therefore the study of a random variable consists in the study of its distribution functions, often referred to simply distribution. The distribution function of any random variable has the following properties: If x is a discrete random variable taking the values x 1
<x 2 < … <x i < … с
вероятностями p 1 <p 2 < … <pi < …, то таблица вида called distribution of a discrete random variable. The distribution function of a random variable with such a distribution has the form A discrete random variable has a stepwise distribution function. For example, for a random number of points that fell out in one throw of a dice, the distribution, distribution function, and distribution function graph look like: If the distribution function Fx(x) is continuous, then the random variable x is called continuous random variable. If the distribution function of a continuous random variable differentiable, then a more visual representation of the random variable gives probability density of random variable p x(x),
which is related to the distribution function Fx(x) formulas From this, in particular, it follows that for any random variable . When solving practical problems, it is often necessary to find the value x, at which the distribution function Fx(x) random variable x takes a given value p, i.e. you need to solve the equation Fx(x) = p. Solutions to such an equation (the corresponding values x) in probability theory are called quantiles. Quantile x p ( p-quantile, level quantile p) a random variable having a distribution function Fx(x), is called the solution xp equations Fx(x) = p,
p(0, 1). For some p the equation Fx(x) = p may have several solutions, for some - none. This means that for the corresponding random variable, some quantiles are not uniquely defined, and some quantiles do not exist. The distribution function of a random variable X is the function F(x), expressing for each x the probability that the random variable X takes the value, smaller x
Example 2.5. Given a series of distribution of a random variable Find and graphically depict its distribution function. Solution. According to the definition F(jc) = 0 for X X F(x) = 0.4 + 0.1 = 0.5 at 4 F(x) = 0.5 + 0.5 = 1 at X > 5. So (see Fig. 2.1): Distribution function properties: 1. The distribution function of a random variable is a non-negative function enclosed between zero and one: 2. The distribution function of a random variable is a non-decreasing function on the entire number axis, i.e. at X 2
>x 3. At minus infinity, the distribution function is equal to zero, at plus infinity, it is equal to one, i.e. 4. Probability of hitting a random variable X in the interval is equal to the definite integral of its probability density ranging from a before b(see Fig. 2.2), i.e. Rice. 2.2 3. The distribution function of a continuous random variable (see Fig. 2.3) can be expressed in terms of the probability density using the formula: F(x)= Jp(*)*. (2.10) 4. Improper integral in infinite limits of the probability density of a continuous random variable is equal to one: Geometric properties / and 4
probability densities mean that its plot is distribution curve - lies not below the x-axis, and the total area of the figure, limited distribution curve and x-axis, is equal to one. For a continuous random variable X expected value M(X) and variance D(X) are determined by the formulas: (if the integral converges absolutely); or (if the reduced integrals converge). Along with the numerical characteristics noted above, the concept of quantiles and percentage points is used to describe a random variable. q level quantile(or q-quantile) is such a valuex qrandom variable, at which its distribution function takes the value, equal to q, i.e. According to example 2.6 find the quantile xqj and 30% random variable point x.
Solution. By definition (2.16) F(xo t3)= 0.3, i.e. ~Y~ = 0.3, whence the quantile x 0 3 = 0.6. 30% random variable point X, or quantile Х)_о,з = xoj» is found similarly from the equation ^ = 0.7. whence *,= 1.4. ? Among the numerical characteristics of a random variable, there are initial v* and central R* k-th order moments, determined for discrete and continuous random variables by the formulas: Probability distribution function and its properties. The probability distribution function F(x) of a random variable X at a point x is the probability that, as a result of the experiment, the random variable will take on a value less than x, i.e. F(x)=P(X< х}. 1. F(-∞)=lim (x→-∞) F(x)=0. Indeed, by definition, F(-∞)=P(X< -∞}. Событие (X < -∞) является невозможным событием: F(-∞)=P{X < - ∞}=p{V}=0. 2. F(∞)=lim (x→∞) F(x)=1, since, by definition, F(∞)=P(X< ∞}. Событие Х < ∞ является достоверным событием. Следовательно, F(∞)=P{X < ∞}=p{U}=1. 3. The probability that a random variable will take a value from the interval [Α Β] is equal to the increment of the probability distribution function on this interval. P(Α ≤ X<Β}=F(Β)-F(Α). 4. F(x 2)≥ F(x 1), if x 2, > x 1, i.e. the probability distribution function is a non-decreasing function. 5. The probability distribution function is continuous on the left. FΨ(x o -0)=limFΨ(x)=FΨ(x o) for x→ x o The differences between the probability distribution functions of discrete and continuous random variables are well illustrated by graphs. Let, for example, a discrete random variable have n possible values, the probabilities of which are P(X=x k )=p k , k=1,2,..n. If x ≤ x 1, then F(X)=0, since there are no possible values of the random variable to the left of x. If x 1< x ≤ x 2 , то левее х находится всего одно возможное значение, а именно, значение х 1 . Hence, F(x)=P(X=x 1 )=p 1. When x 2< x ≤ x 3 слева от х находится уже два возможных значения, поэтому F(x)=P{X=x 1 }+P{X=x 2 }=p 1 +p 2 . Рассуждая аналогично,приходим к выводу, что если х k < x≤ x k+1 , то F(x)=1, так как функция будет равна сумме вероятностей всех возможных значений, которая по условию нормировки равна еденице. Таким образом, график функции распределения дискретной случайной величины является ступенчатым. Возможные значения непрерывной величины располагаются плотно на интервале задания этой величины, что обеспечивает плавное возрастания функции распределения F(x), т.е. ее непрерывность. Consider the probability of a random variable falling into the interval , Δx>0: P(x≤X< x+Δx}=F(x+ Δx)-F(x). Перейдем к пределу при Δx→0: lim (Δx→0) P(x≤ X< x+Δx}=lim (Δx→0) F(x+Δx)-F(x). Предел равен вероятности того, что случайная величина примет значение, равное х. Если функция F(x) непрерывна в точке х, то lim (Δx→0) F(x+Δx)=F(x), т.е. P{X=x}=0. If F(x) has a discontinuity at point x, then the probability P(X=x) will be equal to the jump of the function at that point. Thus, the probability of occurrence of any possible value for a continuous quantity is zero. The expression P(X=x)=0 should be understood as the limit of the probability that a random variable will fall into an infinitely small neighborhood of the point x for P(Α< X≤ Β},P{Α ≤ X< Β},P{Α< X< Β},P{Α ≤ X≤ Β} равны, если Х - непрерывная случайная величина. For discrete variables, these probabilities are not the same in the case when the boundaries of the interval Α and (or) Β coincide with the possible values of the random variables. For a discrete random variable, it is necessary to strictly take into account the type of inequality in the formula P(Α ≤X<Β}=F(Β)-F(Α).Changing Variables Technique

Generalization for the reduce function
Distribution functions

Random variables and distribution functions

Bulk Functions
Independent random variables

Simulation of random variables
Illustrating Probability Transformation


Exponential function and its variables
![]() .
.x 1
x 2
…
x i
…
p 1
p 2
…
pi
…

1
2
3
4
5
6
1/6
1/6
1/6
1/6
1/6
1/6


 and
and ![]() .
.

![]()
![]()



Consider the properties of the function F(x).