
Funkcija diskretne porazdelitve. Porazdelitvena funkcija naključne spremenljivke
Najti:
a) parameter A;
b) porazdelitvena funkcija F(x) ;
c) verjetnost zadetka naključne spremenljivke X v intervalu ;
G) pričakovana vrednost MX in varianca DX.
Narišite funkciji f(x) in F(x).
Naloga 2. Poiščite varianco naključne spremenljivke X, podane z integralno funkcijo.
Naloga 3. Poiščite matematično pričakovanje naključne spremenljivke X dano funkcijo distribucija.
Naloga 4. Gostota verjetnosti neke naključne spremenljivke je podana kot sledi: f(x) = A/x 4 (x = 1; +∞)
Poiščite koeficient A , porazdelitveno funkcijo F(x) , matematično pričakovanje in varianco ter verjetnost, da naključna spremenljivka prevzame vrednost v intervalu . Narišite grafa f(x) in F(x).
Naloga. Porazdelitvena funkcija neke zvezne naključne spremenljivke je podana takole:
Določite parametra a in b , poiščite izraz za gostoto verjetnosti f(x) , matematično pričakovanje in varianco ter verjetnost, da naključna spremenljivka zavzame vrednost v intervalu . Narišite grafa f(x) in F(x).
Poiščimo funkcijo gostote porazdelitve kot odvod funkcije porazdelitve.
F'=f(x)=a
Vemo, da bomo našli parameter a: ![]()
ali 3a=1, od koder je a = 1/3
Parameter b najdemo iz naslednjih lastnosti:
F(4) = a*4 + b = 1
1/3*4 + b = 1, od koder je b = -1/3
Zato je porazdelitvena funkcija: F(x) = (x-1)/3


Razpršenost.

 1 / 9 4 3 - (1 / 9 1 3) - (5 / 2) 2 = 3 / 4
1 / 9 4 3 - (1 / 9 1 3) - (5 / 2) 2 = 3 / 4
Poiščite verjetnost, da naključna spremenljivka prevzame vrednost v intervalu
P(2< x< 3) = F(3) – F(2) = (1/3*3 - 1/3) - (1/3*2 - 1/3) = 1/3
Primer #1. Podana je gostota porazdelitve verjetnosti f(x) zvezne naključne spremenljivke X. Zahtevano:
- Določite koeficient A.
- poiščite porazdelitveno funkcijo F(x) .
- shematično narišite F(x) in f(x) .
- poiščite matematično pričakovanje in varianco X.
- poiščite verjetnost, da X prevzame vrednost iz intervala (2;3).
rešitev:
Naključna spremenljivka X je podana z gostoto porazdelitve f(x):
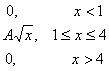
Poiščite parameter A iz pogoja:

oz
14/3*A-1=0
Kje,
A = 3/14

Porazdelitveno funkcijo je mogoče najti s formulo.

Da bi našli porazdelitvene funkcije naključnih spremenljivk in njihovih spremenljivk, je treba preučiti vse značilnosti tega področja znanja. Obstaja več različnih metod za iskanje zadevnih vrednosti, vključno s spreminjanjem spremenljivke in generiranjem trenutka. Distribucija je koncept, ki temelji na elementih, kot so razpršenost, variacije. Vendar pa označujejo le stopnjo razpršitve.
Pomembnejše funkcije naključnih spremenljivk so tiste, ki so povezane in neodvisne ter enakomerno porazdeljene. Na primer, če je X1 teža naključno izbranega posameznika iz moške populacije, X2 teža drugega, ... in Xn teža še ene osebe iz moške populacije, potem moramo vedeti, kako naključna funkcija X je porazdeljena. V tem primeru velja klasični izrek, imenovan centralni mejni izrek. Omogoča nam, da pokažemo, da pri velikih n funkcija sledi standardnim porazdelitvam.
Funkcije ene naključne spremenljivke
Osrednji mejni izrek je zasnovan tako, da približa zadevne diskretne vrednosti, kot sta binom in Poisson. Porazdelitvene funkcije naključnih spremenljivk se obravnavajo predvsem na preprostih vrednostih ene spremenljivke. Na primer, če je X zvezna naključna spremenljivka, ki ima lastno porazdelitev verjetnosti. V tem primeru raziskujemo, kako najti funkcijo gostote Y z uporabo dveh različnih pristopov, in sicer metode porazdelitvene funkcije in spremembe spremenljivke. Prvič, upoštevane so samo vrednosti ena proti ena. Nato morate spremeniti tehniko spreminjanja spremenljivke, da ugotovite njeno verjetnost. Nazadnje se je treba naučiti, kako lahko kumulativna porazdelitev pomaga modelirati naključna števila, ki sledijo določenim zaporednim vzorcem.
Metoda porazdelitve obravnavanih vrednosti
Metoda funkcije porazdelitve verjetnosti naključne spremenljivke je uporabna za iskanje njene gostote. Pri uporabi te metode se izračuna kumulativna vrednost. Nato lahko z razlikovanjem dobite gostoto verjetnosti. Zdaj, ko imamo metodo distribucijske funkcije, si lahko ogledamo še nekaj primerov. Naj bo X zvezna naključna spremenljivka z določeno gostoto verjetnosti.
Kakšna je funkcija gostote verjetnosti x2? Če pogledate ali narišete graf funkcije (zgoraj in desno) y \u003d x2, lahko opazite, da gre za naraščajoči X in 0 V zadnjem primeru smo zelo skrbno indeksirali kumulativne funkcije in gostoto verjetnosti z X ali Y, da bi označili, kateri naključni spremenljivki pripadajo. Na primer, ko smo našli kumulativno porazdelitveno funkcijo Y, smo dobili X. Če morate najti naključno spremenljivko X in njeno gostoto, jo morate le razlikovati. Naj bo X zvezna naključna spremenljivka, podana s porazdelitveno funkcijo s skupnim imenovalcem f(x). V tem primeru, če vnesete vrednost y v X = v (Y), potem dobite vrednost x, na primer v (y). Zdaj moramo dobiti porazdelitveno funkcijo zvezne naključne spremenljivke Y. Kjer prva in druga enakost izhajata iz definicije kumulativnega Y. Tretja enakost velja, ker je del funkcije, za katerega je u (X) ≤ y velja tudi, da je X ≤ v (Y ). In slednje se naredi za določitev verjetnosti v zvezni naključni spremenljivki X. Zdaj moramo vzeti odvod FY (y), kumulativno porazdelitveno funkcijo Y, da dobimo gostoto verjetnosti Y. Naj bo X zvezna naključna spremenljivka s skupnim f(x), definiranim nad c1 Za obravnavo tega vprašanja je mogoče zbrati kvantitativne podatke in uporabiti empirično kumulativno porazdelitveno funkcijo. S temi informacijami in njihovo privlačnostjo morate združiti vzorce srednjih vrednosti, standardne deviacije, podatke o medijih itd. Podobno ima lahko tudi dokaj preprost verjetnostni model ogromno rezultatov. Na primer, če vržete kovanec 332-krat. Potem je število rezultatov, pridobljenih z obračanjem, večje od Googlovega (10100) - število, vendar ne manj kot 100 kvintiljonkrat večje od osnovnih delcev v znanem vesolju. Ne zanima me analiza, ki daje odgovor na vse možne rezultate. Potreben bi bil enostavnejši koncept, kot je število glav ali najdaljša poteza repa. Za osredotočanje na zanimiva vprašanja je sprejet določen rezultat. Definicija v tem primeru je naslednja: naključna spremenljivka je realna funkcija z verjetnostnim prostorom. Razpon S naključne spremenljivke včasih imenujemo prostor stanj. Torej, če je X zadevna vrednost, potem je N = X2, exp ↵X, X2 + 1, tan2 X, bXc itd. Zadnja od teh, zaokroževanje X na najbližje celo število, se imenuje talna funkcija. Ko je distribucijska funkcija, ki nas zanima, določena za naključno spremenljivko x, se običajno pojavi vprašanje: "Kakšne so možnosti, da X pade v neko podmnožico B?" Na primer, B = (lihe številke), B = (večje od 1) ali B = (med 2 in 7), da označite tiste rezultate, ki imajo X, vrednost naključne spremenljivke, v podmnožici A. Torej v zgornjem Na primer, lahko dogodke opišete na naslednji način. (X je liho število), (X je večje od 1) = (X > 1), (X je med 2 in 7) = (2 Tako je mogoče izračunati verjetnost, da bo porazdelitvena funkcija naključne spremenljivke x prevzela vrednosti v intervalu z odštevanjem. Treba je razmisliti o vključitvi ali izključitvi končnih točk. Naključno spremenljivko bomo imenovali diskretna, če ima končen ali šteto neskončen prostor stanj. Tako je X število glav pri treh neodvisnih metih pristranskega kovanca, ki se dvigne z verjetnostjo p. Najti moramo kumulativno porazdelitveno funkcijo diskretne naključne spremenljivke FX za X. Naj bo X število vrhov v zbirki treh kart. Potem je Y = X3 preko FX. FX se začne pri 0, konča pri 1 in se ne zmanjša, ko se vrednosti x povečajo. Funkcija kumulativne porazdelitve FX diskretne naključne spremenljivke X je konstantna, razen pri skokih. Pri skakanju je FX neprekinjen. Trditev o pravilni kontinuiteti porazdelitvene funkcije je mogoče dokazati iz lastnosti verjetnosti z uporabo definicije. Sliši se takole: konstantna naključna spremenljivka ima kumulativni FX, ki ga je mogoče razlikovati. Da pokažemo, kako se to lahko zgodi, lahko navedemo primer: tarča z enoto polmera. Verjetno. puščica je enakomerno porazdeljena po določenem območju. Za nekatere λ> 0. Tako porazdelitvene funkcije zveznih naključnih spremenljivk gladko naraščajo. FX ima lastnosti distribucijske funkcije. Moški čaka na avtobusni postaji, dokler avtobus ne prispe. Sam se je odločil, da bo zavrnil, ko bo čakanje doseglo 20 minut. Tukaj je treba najti kumulativno porazdelitveno funkcijo za T. Čas, ko bo oseba še na avtobusni postaji ali ne bo odšla. Kljub temu, da je kumulativna porazdelitvena funkcija definirana za vsako slučajno spremenljivko. Kljub temu se bodo precej pogosto uporabljale druge karakteristike: masa za diskretno spremenljivko in funkcija porazdelitve gostote naključne spremenljivke. Običajno je vrednost izhodna skozi eno od teh dveh vrednosti. Te vrednosti upoštevajo naslednje lastnosti, ki so splošnega (masovnega) značaja. Prvi temelji na dejstvu, da verjetnosti niso negativne. Drugi izhaja iz opažanja, da nabor za vse x=2S, prostor stanj za X, tvori particijo verjetnostne svobode X. Primer: meti pristranskega kovanca, katerih rezultati so neodvisni. Lahko nadaljujete z izvajanjem določenih dejanj, dokler ne dobite meta glav. Naj X označuje naključno spremenljivko, ki podaja število repov pred prvo glavo. In p označuje verjetnost v katerem koli dejanju. Torej ima verjetnostna funkcija mase naslednje značilnosti. Ker izrazi tvorijo numerično zaporedje, X imenujemo geometrijska naključna spremenljivka. Geometrijska shema c, cr, cr2,. , crn ima vsoto. In zato ima sn mejo kot n 1. V tem primeru je meja neskončna vsota. Zgornja masna funkcija tvori geometrijsko zaporedje z razmerjem. Torej naravni števili a in b. Razlika v vrednosti v funkciji porazdelitve je enaka vrednosti funkcije mase. Obravnavane vrednosti gostote imajo naslednjo definicijo: X je naključna spremenljivka, katere porazdelitev FX ima derivat. FX, ki ustreza Z xFX (x) = fX (t) dt-1, se imenuje funkcija gostote verjetnosti. In X se imenuje zvezna naključna spremenljivka. V temeljnem izreku računa je funkcija gostote odvod porazdelitve. Verjetnosti lahko izračunate z izračunom določenih integralov. Ker se podatki zbirajo iz več opazovanj, je treba za modeliranje eksperimentalnih postopkov upoštevati več kot eno naključno spremenljivko hkrati. Zato nabor teh vrednosti in njihova skupna porazdelitev za obe spremenljivki X1 in X2 pomeni ogled dogodkov. Za diskretne naključne spremenljivke so definirane skupne verjetnostne masne funkcije. Pri zveznih se upoštevata fX1, X2, kjer je zadoščena skupna gostota verjetnosti. Dve naključni spremenljivki X1 in X2 sta neodvisni, če sta katera koli dva dogodka, povezana z njima, enaka. Z besedami je verjetnost, da se zgodita dva dogodka (X1 2 B1) in (X2 2 B2) hkrati, y, enaka zmnožku zgornjih spremenljivk, da se vsak od njiju zgodi posebej. Za neodvisne diskretne naključne spremenljivke obstaja skupna verjetnostna masna funkcija, ki je produkt mejnega volumna ionov. Za zvezne naključne spremenljivke, ki so neodvisne, je skupna funkcija gostote verjetnosti produkt mejnih vrednosti gostote. Nazadnje se upošteva n neodvisnih opazovanj x1, x2. , xn, ki izhaja iz neznane gostotne ali masne funkcije f. Na primer neznani parameter v funkcijah za eksponentno naključno spremenljivko, ki opisuje čakalni čas za avtobus. Glavni cilj tega teoretičnega področja je zagotoviti orodja, potrebna za razvoj sklepnih postopkov, ki temeljijo na trdnih načelih statistične znanosti. Tako je zelo pomemben primer uporabe programske opreme zmožnost ustvarjanja psevdopodatkov za posnemanje dejanskih informacij. To omogoča testiranje in izboljšanje analiznih metod, preden jih je treba uporabiti v resničnih bazah podatkov. To je potrebno za raziskovanje lastnosti podatkov z modeliranjem. Za številne običajno uporabljene družine naključnih spremenljivk R ponuja ukaze za njihovo generiranje. V drugih okoliščinah bodo potrebne metode za modeliranje zaporedja neodvisnih naključnih spremenljivk, ki imajo skupno porazdelitev. Diskretne naključne spremenljivke in vzorčni ukaz. Ukaz sample se uporablja za ustvarjanje preprostih in stratificiranih naključnih vzorcev. Posledično, če je vneseno zaporedje x, sample(x, 40) izbere 40 zapisov iz x, tako da imajo vse izbire velikosti 40 enako verjetnost. To uporablja privzeti ukaz R za pridobivanje brez zamenjave. Lahko se uporablja tudi za modeliranje diskretnih naključnih spremenljivk. Če želite to narediti, morate zagotoviti prostor stanj v vektorju x in masno funkcijo f. Klic za zamenjavo = TRUE označuje, da pride do vzorčenja z zamenjavo. Nato se za vzorec n neodvisnih naključnih spremenljivk, ki imajo skupno masno funkcijo f, uporabi vzorec (x, n, zamenjaj = TRUE, verjetnost = f). Ugotovljeno je, da je 1 najmanjša predstavljena vrednost, 4 pa največja od vseh. Če je ukaz prob = f izpuščen, bo vzorec enakomerno vzorčen iz vrednosti v vektorju x. Simulacijo lahko primerjate z masno funkcijo, ki je ustvarila podatke, tako da pogledate dvojni znak enačaja ==. In preračunavanje opazovanj, ki imajo vse možne vrednosti za x. Lahko naredite mizo. To ponovite za 1000 in primerjajte simulacijo z ustrezno masno funkcijo. Najprej simulirajte homogene porazdelitvene funkcije naključnih spremenljivk u1, u2,. , un na intervalu . Približno 10 % številk mora biti znotraj . To ustreza 10 % simulacijam na intervalu za naključno spremenljivko s prikazano funkcijo porazdelitve FX. Podobno mora biti približno 10 % naključnih števil v intervalu . To ustreza 10 % simulacijam na intervalu naključne spremenljivke s porazdelitveno funkcijo FX. Te vrednosti na osi x lahko dobite tako, da vzamete obratno vrednost iz FX. Če je X zvezna naključna spremenljivka z gostoto fX pozitivno povsod v svoji domeni, potem je porazdelitvena funkcija strogo naraščajoča. V tem primeru ima FX inverzno funkcijo FX-1, znano kot kvantilna funkcija. FX (x) u samo, če je x FX-1 (u). Verjetnostna transformacija izhaja iz analize naključne spremenljivke U = FX(X). FX ima razpon od 0 do 1. Ne more sprejeti vrednosti pod 0 ali nad 1. Za vrednosti u med 0 in 1. Če je U mogoče modelirati, je treba simulirati naključno spremenljivko s porazdelitvijo FX preko kvantilne funkcije. Vzemite odvod, da vidite, da se gostota u spreminja znotraj 1. Ker ima naključna spremenljivka U konstantno gostoto v intervalu svojih možnih vrednosti, se imenuje enakomerna na intervalu. Modeliran je v R z ukazom runif. Identiteta se imenuje verjetnostna transformacija. Kako deluje, si lahko ogledate na primeru deske za pikado. X med 0 in 1, porazdelitvena funkcija u = FX(x) = x2 in s tem kvantilna funkcija x = FX-1(u). Možno je modelirati neodvisna opazovanja razdalje od središča plošče pikado, hkrati pa generirati enotne naključne spremenljivke U1, U2,. , Un. Porazdelitvena funkcija in empirična funkcija temeljita na 100 simulacijah porazdelitve pikado deske. Za eksponentno naključno spremenljivko je verjetno u = FX (x) = 1 - exp (- x) in s tem x = - 1 ln (1 - u). Včasih je logika sestavljena iz enakovrednih izjav. V tem primeru morate združiti dva dela argumenta. Identiteta presečišča je podobna za vsa 2 (S i i) S, namesto neke vrednosti. Unija Ci je enaka prostoru stanj S in vsak par se med seboj izključuje. Ker je Bi - razdeljen na tri aksiome. Vsako preverjanje temelji na ustrezni verjetnosti P. Za katero koli podmnožico. Uporaba identitete za zagotovitev, da odgovor ni odvisen od tega, ali so vključene končne točke intervala. Za vsak izid v vseh dogodkih se na koncu uporabi druga lastnost kontinuitete verjetnosti, ki velja za aksiomatično. Zakon porazdelitve funkcije naključne spremenljivke tukaj kaže, da ima vsaka svojo rešitev in odgovor. Rezultat katerega koli naključnega poskusa je mogoče kvalitativno in kvantitativno označiti. Kakovostno rezultat naključnega eksperimenta - naključen
dogodek. Kaj kvantitativna značilnost, ki lahko kot rezultat naključnega eksperimenta sprejme eno od določenega niza vrednosti, - naključna vrednost. Naključna vrednost
je eden osrednjih konceptov teorije verjetnosti. Naj bo poljuben verjetnostni prostor. Naključna spremenljivka je realna numerična funkcija x \u003d x (w), w W , tako da za vsako realno x Dogodek
običajno zapisano kot x< x. V nadaljevanju bomo naključne spremenljivke označevali z malimi grškimi črkami x, h, z, …
Naključna spremenljivka je število točk, ki so padle pri metanju kocke, ali višina študenta, naključno izbranega iz študijske skupine. V prvem primeru imamo opravka z diskretna naključna spremenljivka(vzame vrednosti iz diskretnega niza številk M=(1, 2, 3, 4, 5, 6) ; v drugem primeru z neprekinjeno naključna spremenljivka(vzema vrednosti iz zveznega niza števil - iz intervala številske premice jaz=). Vsaka naključna spremenljivka je popolnoma določena s svojo distribucijska funkcija. Če je x naključna spremenljivka, potem je funkcija F(x) = Fx(x)
= p(x< x) je poklican distribucijska funkcija naključna spremenljivka x. Tukaj p(x<x) - verjetnost, da naključna spremenljivka x zavzame vrednost manjšo od x. Pomembno je razumeti, da je porazdelitvena funkcija "potni list" naključne spremenljivke: vsebuje vse informacije o naključni spremenljivki in torej preučevanje naključne spremenljivke je sestavljeno iz preučevanja njenega distribucijske funkcije, pogosto omenjeno preprosto distribucija. Funkcija porazdelitve katere koli naključne spremenljivke ima naslednje lastnosti: Če je x diskretna naključna spremenljivka, ki prevzame vrednosti x 1
<x 2 < … <x i < … с
вероятностями str 1 <str 2 < … <pi < …, то таблица вида klical porazdelitev diskretne naključne spremenljivke. Porazdelitvena funkcija naključne spremenljivke s takšno porazdelitvijo ima obliko Diskretna naključna spremenljivka ima funkcijo stopenjske porazdelitve. Na primer, za naključno število točk, ki so padle v enem metu kocke, so porazdelitev, porazdelitvena funkcija in graf porazdelitvene funkcije videti takole: Če distribucijska funkcija Fx(x) je zvezna, potem se pokliče naključna spremenljivka x zvezna naključna spremenljivka. Če porazdelitvena funkcija zvezne naključne spremenljivke razločljiv, potem dobimo bolj vizualno predstavitev naključne spremenljivke gostota verjetnosti naključne spremenljivke p x(x),
ki je povezana z distribucijsko funkcijo Fx(x) formule Iz tega zlasti sledi, da je za vsako naključno spremenljivko . Pri reševanju praktičnih problemov je pogosto treba najti vrednost x, pri kateri je distribucijska funkcija Fx(x) naključna spremenljivka x ima dano vrednost str, tj. rešiti morate enačbo Fx(x) = str. Rešitve takšne enačbe (ustrezne vrednosti x) v teoriji verjetnosti imenujemo kvantili. Kvantil x p ( str-kvantil, kvantil ravni str) naključna spremenljivka s porazdelitveno funkcijo Fx(x), se imenuje rešitev xp enačbe Fx(x) = str,
str(0, 1). Za nekatere str enačba Fx(x) = str ima lahko več rešitev, za nekatere - nobene. To pomeni, da za ustrezno naključno spremenljivko nekateri kvantili niso enolično definirani, nekateri kvantili pa ne obstajajo. Porazdelitvena funkcija naključne spremenljivke X je funkcija F(x), ki izraža za vsak x verjetnost, da naključna spremenljivka X prevzame vrednost, manjši x
Primer 2.5. Podana vrsta porazdelitve naključne spremenljivke Poiščite in grafično prikažite njegovo porazdelitveno funkcijo. rešitev. Po definiciji F(jc) = 0 za X X F(x) = 0,4 + 0,1 = 0,5 pri 4 F(x) = 0,5 + 0,5 = 1 pri X > 5. Torej (glej sliko 2.1): Lastnosti porazdelitvene funkcije: 1. Porazdelitvena funkcija naključne spremenljivke je nenegativna funkcija, ki je zaprta med nič in ena: 2. Porazdelitvena funkcija naključne spremenljivke je nepadajoča funkcija na celotni številski osi, tj. pri X 2
>x 3. Pri minus neskončnosti je porazdelitvena funkcija enaka nič, pri plus neskončnosti pa ena, tj. 4. Verjetnost zadetka naključne spremenljivke X v intervalu je enak določenemu integralu njegove gostote verjetnosti, ki sega od a prej b(glej sliko 2.2), tj. riž. 2.2 3. Porazdelitveno funkcijo zvezne naključne spremenljivke (glej sliko 2.3) lahko izrazimo v smislu gostote verjetnosti z uporabo formule: F(x)= Jp(*)*. (2,10) 4. Nepravilni integral v neskončnih mejah gostote verjetnosti zvezne naključne spremenljivke je enak ena: Geometrijske lastnosti / in 4
gostote verjetnosti pomenijo, da je njen zaplet porazdelitvena krivulja - ne leži pod osjo x, in celotno površino figure, krivulja omejene porazdelitve in os x, je enako ena. Za zvezno naključno spremenljivko X pričakovana vrednost M(X) in varianco D(X) se določijo po formulah: (če integral konvergira absolutno); oz (če zmanjšani integrali konvergirajo). Skupaj z zgoraj navedenimi numeričnimi značilnostmi se za opis naključne spremenljivke uporablja koncept kvantilov in odstotnih točk. kvantil ravni q(oz q-kvantil) je taka vrednostx qnaključna spremenljivka, pri kateri njena distribucijska funkcija dobi vrednost, enako q, tj. Glede na primer 2.6 poiščite kvantil xqj in 30 % točka naključne spremenljivke x.
rešitev. Po definiciji (2.16) je F(xo t3)= 0,3, tj. ~Y~ = 0,3, od koder kvantil x 0 3 = 0,6. 30 % točka naključne spremenljivke X, ali kvantil Х)_о,з = xoj» najdemo podobno iz enačbe ^ = 0,7. od koder je *,= 1,4. ? Med numeričnimi značilnostmi naključne spremenljivke so začetnica v* in osrednji R* trenutki k-tega reda, določeno za diskretne in zvezne naključne spremenljivke po formulah: Funkcija porazdelitve verjetnosti in njene lastnosti. Funkcija porazdelitve verjetnosti F(x) naključne spremenljivke X v točki x je verjetnost, da bo zaradi poskusa naključna spremenljivka prevzela vrednost, manjšo od x, tj. F(x)=P(X< х}. 1. F(-∞)=lim (x→-∞) F(x)=0. Dejansko je po definiciji F(-∞)=P(X< -∞}. Событие (X < -∞) является невозможным событием: F(-∞)=P{X < - ∞}=p{V}=0. 2. F(∞)=lim (x→∞) F(x)=1, saj je po definiciji F(∞)=P(X< ∞}. Событие Х < ∞ является достоверным событием. Следовательно, F(∞)=P{X < ∞}=p{U}=1. 3. Verjetnost, da bo naključna spremenljivka prevzela vrednost iz intervala [Α Β], je enaka prirastku funkcije porazdelitve verjetnosti na tem intervalu. P(Α ≤X<Β}=F(Β)-F(Α). 4. F(x 2)≥ F(x 1), če je x 2, > x 1, tj. funkcija porazdelitve verjetnosti je nepadajoča funkcija. 5. Funkcija porazdelitve verjetnosti je zvezna na levi strani. FΨ(x o -0)=limFΨ(x)=FΨ(x o) za x→ x o Razlike med funkcijami porazdelitve verjetnosti diskretnih in zveznih naključnih spremenljivk so dobro ponazorjene z grafi. Naj ima na primer diskretna naključna spremenljivka n možnih vrednosti, katerih verjetnosti so P(X=x k )=p k , k=1,2,..n. Če je x ≤ x 1, potem je F(X)=0, ker levo od x ni možnih vrednosti naključne spremenljivke. Če je x 1< x ≤ x 2 , то левее х находится всего одно возможное значение, а именно, значение х 1 . Zato je F(x)=P(X=x 1 )=p 1. Ko je x 2< x ≤ x 3 слева от х находится уже два возможных значения, поэтому F(x)=P{X=x 1 }+P{X=x 2 }=p 1 +p 2 . Рассуждая аналогично,приходим к выводу, что если х k < x≤ x k+1 , то F(x)=1, так как функция будет равна сумме вероятностей всех возможных значений, которая по условию нормировки равна еденице. Таким образом, график функции распределения дискретной случайной величины является ступенчатым. Возможные значения непрерывной величины располагаются плотно на интервале задания этой величины, что обеспечивает плавное возрастания функции распределения F(x), т.е. ее непрерывность. Upoštevajte verjetnost, da naključna spremenljivka pade v interval Δx>0: P(x≤X< x+Δx}=F(x+ Δx)-F(x). Перейдем к пределу при Δx→0: lim (Δx→0) P(x≤ X< x+Δx}=lim (Δx→0) F(x+Δx)-F(x). Предел равен вероятности того, что случайная величина примет значение, равное х. Если функция F(x) непрерывна в точке х, то lim (Δx→0) F(x+Δx)=F(x), т.е. P{X=x}=0. Če ima F(x) diskontinuiteto v točki x, potem bo verjetnost P(X=x) enaka skoku funkcije v tej točki. Tako je verjetnost pojava katere koli možne vrednosti za neprekinjeno količino enaka nič. Izraz P(X=x)=0 je treba razumeti kot mejo verjetnosti, da bo naključna spremenljivka padla v neskončno majhno okolico točke x za P(Α< X≤ Β},P{Α ≤ X< Β},P{Α< X< Β},P{Α ≤ X≤ Β} равны, если Х - непрерывная случайная величина. Za diskretne spremenljivke te verjetnosti niso enake v primeru, ko meje intervala Α in (ali) Β sovpadajo z možnimi vrednostmi naključnih spremenljivk. Za diskretno naključno spremenljivko je treba strogo upoštevati vrsto neenakosti v formuli P(Α ≤X<Β}=F(Β)-F(Α).Tehnika spreminjanja spremenljivk

Posplošitev za funkcijo redukcije
Distribucijske funkcije

Naključne spremenljivke in porazdelitvene funkcije

Množične funkcije
Neodvisne naključne spremenljivke

Simulacija naključnih spremenljivk
Ponazoritev verjetnostne transformacije


Eksponentna funkcija in njene spremenljivke
![]() .
.x 1
x 2
…
x i
…
str 1
str 2
…
pi
…

1
2
3
4
5
6
1/6
1/6
1/6
1/6
1/6
1/6


 in
in ![]() .
.

![]()
![]()



Razmislite o lastnostih funkcije F(x).